

In the previous article (The Big Data SIEM: Ingestion Layer with Azure) we establish a baseline of principles with which to ingest data at the multiple petabyte per day scale. Though many aspects align to lessons learned in review of Azure’s Well Architected Framework(WAF), we include our recommendations for API client calls, data transformations, team composition and other quality of life improvements for the implementation phase. As you’ll recall, we stopped a bit short in the “Loading & Storage” level of the ETL/ELT layer, as it often has a lot of overlap with storage configuration.
In this post, we’ll continue by diving into just that: The storage layer of the Big Data SIEM. We’ll walk through some of our considerations while planning phases and configure it to interact with the ingestion and plan for the detection layers, as well as future workloads in analytics and MLops. Finally, we’ll wrap up with the benefits of creating a Data Lifecycle Management(DLM) process, and make recommendations on what your team composition should look like for implementation. Though this post is tailored to the multiple petabyte per day ingestion rate (see scenario overview), its design follows principles which can be scaled in either direction, as well as the ability to adapt to future workloads which may not be defined at the time of implementation.
As we aim to provide guidance in support of your Big Data SIEM journey, each post in this series is written conversationally, assuming (a) the reader has some exposure to cloud technologies, (b) that a project goal is to mitigate administrative overhead where possible and © that you must utilize technologies and services included within the Azure SLA. The final post for each series will feature “advice I would give a friend”, which breaks outside each provider’s SLA to achieve the highest level of performance possible. The solutions suggested outside the cloud native SLA align towards a DevOps centric methodology and interoperability across clouds and environments.
As always, hyperlinks are provided for documentation, quick-starts or introductions for all technologies and methodologies. Comments are disabled for this post, but you can reach out to Tyson Barber and Tyler G. if you have specific questions.
Disclaimers
As the Azure native and supported SIEM we will speak to its use and its underlying technologies within the Big Data SIEM (specifically: Log Analytics) to the extent that they are involved with storage configurations and data life-cycle management. Keep in mind that your specific use of these services will vary depending on many variables.
Further, and while we are excited to learn more about the performance advantages of Microsoft’s new Auxiliary Logs, this service was in “preview” at the time of this writing. As our readers who have worked with us in the past will know; it is extremely rare that either of us will recommend the use of services in preview status for your main workflow.
Storage Design
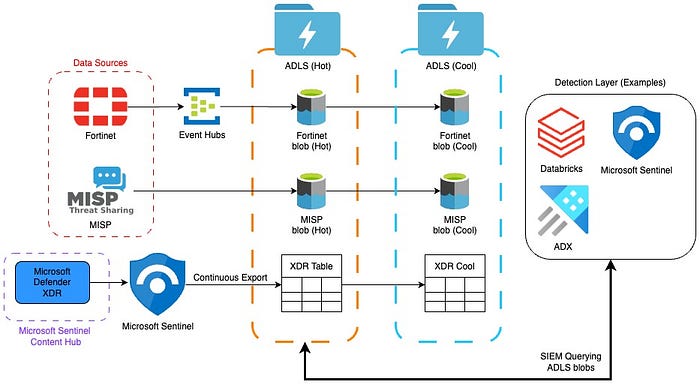
As mentioned in our series intro: An efficient storage configuration is designed to minimize the volume of data ingested and stored by compute & detection services, as these begin to layer on (and multiply) the costs of stored data. This is a fairly common mistake on behalf of decision makers and architects alike, in that the pursuit of near real-time detections often pushes them to position compute & detection technologies at the center of their architecture, where the storage really should be. In later articles we’ll discuss detection models that include traditional SIEMs, MLops, and other strategies to utilize this data.
While this may work well up to a small to lower-mid sized ingestion scale in Azure, compute-layer technologies often present the following challenges while ingesting data at the scale of the Big Data SIEM:
- Lack of fine-grain storage policies, forcing all data into “Hot” storage as a standard
- Inability to build an optimized Data Life-Cycle Management (DLM) pipeline for aging data
- Storage cost multipliers, simply for storage being bundled with the compute technology
- Underlying storage technologies are often not the cloud providers flagship service offering for ingestion at this scale, and thus not optimized for our use-case scenario
- Lower scalability for increased number of data sources or events per second
- Less insight into your data, as embedded storage services restrict custom data workloads and scripts
- Less flexibility to run separate workloads in parallel as future needs demand, such as those connected to the serve/visualization, analytics and MLops layers
By implementing one methodological change (shown in the image above) which shifts reliance from embedded storage to designated storage, we’re able to enhance the performance of your architecture to the point where it is capable of handling multiple petabytes of ingested data per day, without making any of the above listed sacrifices, and saving many millions of dollars per month. In fact: change recommendations of this nature recently provided a client with the option to save upwards of $60 million per year in their data storage overhead.
Azure Data Lake Storage Gen2
At the core of the storage layer is Azure Data Lake Storage Gen2(ADLS) rather than Sentinel’s Log Analytics Workspace (aka Microsoft Sentinel workspace), or the underlying Blob storage with Azure Data Explorer(ADX). The reason for this is that ADLS enhancements from regular blob storage optimize cost and performance, provide massive scalability, query acceleration, and have ability to work with all frameworks that use the Apache Hadoop Distributed File System (HDFS). Though future analytic and workloads might be a secondary objective, it’s important to note that data analysis frameworks that use HDFS as their data access layer can directly access Azure Data Lake Storage data through the Azure Blob File System(ABFS) — which includes the Apache Spark analytics engine (a core technology to Databricks).
Though the (simplified) diagram above shows only two storage accounts (Hot and Cool), it is common to see Hot, Cool, Cold and Archival, often with multiples of each in order to ingest, store, and organize cost optimized data at this scale.
Loading Data from Event Hubs
For the data sources being ingested with Azure Event Hubs, we recommend the use of Azure Event Hubs Capture, which allows us to automatically load data streaming through Azure Event Hubs into our ADLS container of choice. Configuration for Event Hubs Capture is very straightforward and should not take much time or effort form your integration team.
It’s also worth mentioning that Azure Event Hubs natively supports Apache Kafka, which allows you to use Kafka clients to send and receive messages from Azure Event Hubs without changing the client code. Most of the configuration for this is on the Kafka client side, which includes configuring Event Hubs namespace and connection string.
Author’s Recommendation
The main issue that I’ve seen within workloads using Event Hubs is that it is often not properly configured for workloads featuring multiple data sources, or even data sources with high volumes of events per second. Event Hubs Capture is highly stable and can handle millions of events per second, so if you’re having issues as you creep closer to the PB/Day scale, it’s likely due to your Event Hubs partition configuration.
External Tables with Microsoft Sentinel
An external table is a schema entity that references data stored external to the Kusto database within Azure Data Explorer(ADX), Microsoft Fabric or Microsoft Sentinel. The advantage to external tables is that we’re able to use Kusto Query Language(KQL) from within these three services, to query data stored within ADLS containers; thereby mitigating (massively) the volume of data we are required to ingest or retain into detection-layer services while yielding accelerated query speeds.
Further, storing the data within ADLS allows for fine-grained storage policies and Data Lifecycle Management, and provides a solution more capable of scaling into future analytics. AI and MLops workloads, many of which are built on top of the data lake architecture.
Author’s Recommendation
Though it can be procured in other ways, a simple method of ingestion for the out-of-the-box content offered by Microsoft Is to enable it from the Microsoft Sentinel Content Hub. However, even if you’re planning to use Microsoft Sentinel as your SIEM, we would recommend exporting all data from Sentinel Workspace (aka, Log Analytics Workspace) through a continuous export job, meeting your requirements for retention and the specifics of your workflow.
Data Lifecycle Management
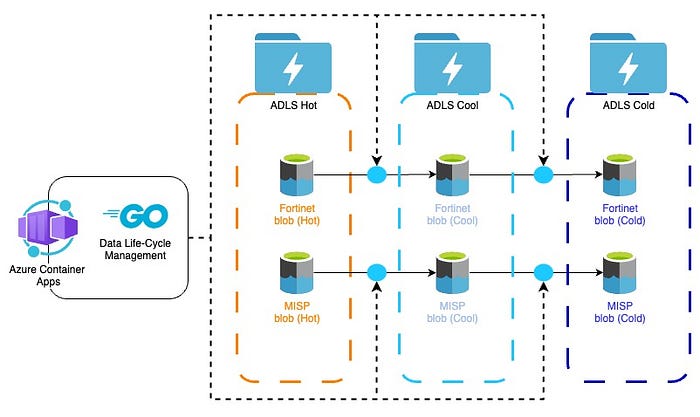
At the petabyte per day scale, a major factor in storage costs correlates to the manner in which data is stored, accessed and archived. Unfortunately, we’ve all seen environments where all data is either going to a Hot storage volume and stored there indefinitely, or the inverse where all data is sent to Cool / Cold at a high transaction rate. In both of these scenarios (and most in between), the architects were half correct and focused on a design that was for less retention and ingestion or constrained implementation financial and/or time budget. This unfortunately leads them to a solution that burns money at an 8x to 10x rate for the same data ingestion and transactional volumes.
The remedy in this type situation is a Data Life-cycle Management(DLM) process designed to move data between storage tiers (or temperatures), which is optimized to your organization’s workflow with the data. While planning your DLM, remember that “Hot” storage types have inexpensive transaction rates, with high data storage costs. On the other side of the spectrum, Cold & Archival storage types have high transaction costs, with extremely low data storage rates.
As seen in the diagram above, transitioning data between tiers of storage is handled through multiple Azure Container Apps running Go (https://go.dev/) files, converted into docker images. Though this could be handled with Kubernetes, we often recommend Azure Container Apps to those looking to mitigate administrative overhead, due to its flat learning curve and given that its high modularity enables it to adapt to future workloads.
For those of you like Tyler G, who are interested in either implementing new automated ML, ANN or LLM systems, or siphoning and enriching some of the data through the medallion architecture into dataset for training; the area between the hot and cold storage would be a place of interest.
Author’s Recommendation
For simplicity sake, the diagram above shows all new data entering the Hot storage, then being aged out into cooler and cooler tiers. The best advice that I could give anyone here, is to align the optimized DLM plan to regulatory and compliance requirements and to consult your SOC and Threat Hunting teams to ensure a sufficiently sized hot storage while moving data continually into cheaper tiers. Consulting past investigations and incidents for search periods should provide good guidance on cool tier allocation..
For example: A lot of detections are run immediately upon alert data entering the architecture, and the manual or scheduled queries might be fairly rare after the 3 day mark. If this were the case for your workflow, you might think about transitioning a lot of this data to a cooler tier after the first 72 hours.
I would also recommend that you read up on your compliance requirements to ensure that there is no language around “hot” or “cold”, but rather that your investigations teams are able to query data within a certain amount of time. With Azure, there isn’t much of a query speed difference between hot, cool or cold data storage accounts, so if your compliance requirement on data that’s more than 45 days old is just to be able to query and run detections within 20 or 30 minutes — you’re covered without having to pay hot tier pricing.
Implementation
For this aspect of the Big Data SIEM, we’re fortunate for the fact that the bulk of complexity lies within the planning and calculation phases of the storage layer, rather than implementation itself. With the right direction and given enough detail in the project plan, the implementation team should be able to breeze through this
A Brief Word on Implementation Workflow
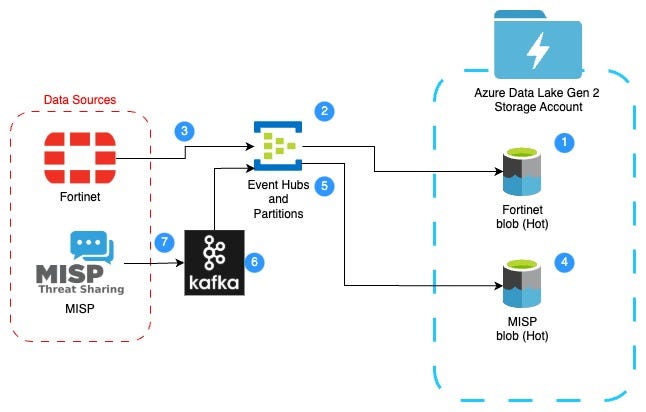
As seen in the diagram above, a rolling release working in reverse order is recommended; starting from the ADLS Hot storage container, to your Event Hubs Partition, to on-boarding the data source — one data source at a time. While multiple data source pipelines can be constructed in tandem, we always recommend starting with the data landing spot first.
Layering on additional data sources and ingestion methods becomes easier as you implement a templated IaC (Infrastructure as Code) strategy such as using Terraform to create the assets. Using this method adding additional Event Hubs and partitions for data sources or sub data sources such as regional or duplicative sources from various clouds or subscriptions. Taking this same approach you can connect Syslog, Azure Data Factory (ADF), Databricks or other messaging services like RabbitMQ. For ingestion from RDBMS (SQL), Snowflake, or even other Datalakes where the data resides and is not streamed into the Big Data SIEM you will still use the same methodologies but will rely on additional compute as discussed in our ingestion layer article.
Team Composition
As we’ve discussed above, there is some nuance while configuring your storage. However, the following composition should be able to knock out the majority of your data sources with minimal support.
- Technical Project Manager(TPM): A good technical project manager will orchestrate development of the storage layer, while communicating NPV advantages to one solution or the next, as forks in the road to implementation arise. The TPM will also work with the Principle Architect to run projections on a fiscally optimized data storage framework, and help provide guidance on compliance requirements for data retention.
- DevOps: Within this layer of implementation, the DevOps engineer will be focused on the task involving KQL, Python and other queries (such as the continuous export jobs from Log Analytics), ensuring that the Azure Container Apps are configured properly, and to make changes to Go file responsible for your DLM process.
- Security Engineer / SME: For this layer, the ideal Security Engineer has 5+ years of experience with storage, data streaming platforms (such as Event Hubs and Kafka) and some API development. The Security Engineer will be primarily focused on configuring the components and connections seen in this post.
Generally, I would recommend one TPM & DevOps Engineer, with 4–5 Security Engineers or Architects for the implementation phase of this layer — including both senior and junior levels. While the DevOps Engineer’s involvement is more limited in scope, the Security Engineers will often need to tag-team development, documentation and testing to connect a data source to the Hot container. The number of engineers can adjust based on total available time. We make two assumptions, one being that 4–5 engineers have regular “day jobs” and may not be fully dedicated to this work and two, this includes multiple petabytes per day requiring testing and validation throughout.
Implementation Timeline
I don’t want to give the ‘consultant answer’ here, but the implementation timeline for this layer really just depends on how your implementation team prepares ahead of starting work. Ideally, they come to the table with a library of Terraform IaC templates which represent key components of this architecture. If they have these on hand, then the implementation could take just weeks (regardless of the number of data sources & pipelines), as they would spend most of their time modifying the framework rather than building the resources and connections by hand. Unfortunately, these skills are somewhat rare within the IT industry, and building a library of deployable templates would require an investment which most companies are not prepared to make.
On the other side, the implementation team might spend a lot of time adding details to their project plan but hit the launch date with no templates or code in hand. For this team, it might take many months if they were solely focused on the nuances of the storage layer making continuous changes and manual rework reducing project speed.
Closing Thoughts
If the techniques discussed above are implemented correctly and with the correct types of personnel, the storage layer of your big data SIEM should yield a very high level of compute and fiscal performance, given the volume of data being ingested and stored. Azure has some incredible services which are capable of handling immense data ingestion and storage scale — if configured properly.
Again, we hope that this post brings some value to your projects, whether you’re in a planning or recovery phase. Please feel free to reach out to Tyson Barber and Tyler G. if you have any questions, comments or corrections — we would be happy to connect and share our thoughts on LinkedIn.