
In our previous article (The Big Data SIEM), we opened the series with a tongue and cheek scenario, a detailed use-case and general overview of the basic four layers to the big-data SIEM as we (Tyson Barber and Tyler G.) like to frame them in the minds of decision makers on these types of projects. If you haven’t had the opportunity to view that post, it may be useful context before continuing.
In this post, we walk through some of the design considerations which should be addressed early in the planning phases of your new SIEM’s Ingestion pipeline. We aim to guide the design and leadership teams with specific design considerations, and (hopefully) help you avoid some of the more common mistakes we’ve witnessed as third-party consultants. Though this post is tailored to the multiple petabyte per day ingestion rate (see scenario overview), its design follows principles which can be scaled in either direction to fit your specific needs. To wrap things up, we’ll discuss the implementation team composition, expectations and timetables for completion given the variables shared in the Scenario & Business Use-case for the series intro.
If some of the principles or design considerations covered are contrary to your current architecture, don’t worry: Implementing some or all of our recommendations is fairly straightforward with the right plan and team composition.
Through this series, we provide high to medium level guidance in support of your Big Data SIEM migration. These are written conversationally assuming the reader has some level of exposure to cloud technologies. Hyperlinks will be provided for all key technologies and references. We’ve disabled comments, but you can reach out to Tyson Barber and Tyler G. if you have specific questions concerning something discussed in the article.
A Word of Caution
Though myself and many others tend to design cloud architectures backwards from the data’s end-use cases (or ‘running detections’ in this scenario), this design approach can be somewhat of a trap within the ingestion (or ETL) aspect of the Big Data SIEM scenario in that it leads to placing compute and detection layer technologies at the center of the architecture, combining storage and compute, reducing flexibility and increasing cost. This includes services such as Azure Data Explorer(ADX), Microsoft Sentinel, Azure Stream Analytics, which seem like magic-bullet solutions to those thinking purely in terms of “how quickly can I run detections after the data is generated at the source”.
I get it — that’s our goal too. However, a simple way to avoid this pitfall is to encourage your team to think of the data as “just data” for the ingestion layer of the architecture. Implementing this design builds the capabilities needed to implement multiple technologies, supporting Data Science, Machine Learning and AI workloads. Try to keep this in mind as we work through this article. I promise that it will save you a lot of heartache in the future.
Ingestion Design Considerations
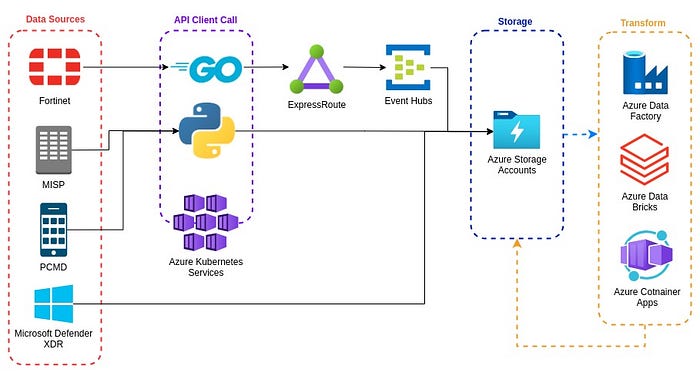
Within the context of this series: The ingestion process (commonly referred to as ETL) seeks to efficiently ingest threat intelligence, syslog, firewall and other datasets from their source into your Azure cloud-based storage. From there, Detection Engineering, Threat Hunters, Threat Intelligence and Security Operation Center team members will run both scheduled and ad-hoc queries within these datasets to detect threats to your organization’s infrastructure and customer devices.
Keep in mind that while the primary goals of our efforts in this layer must meet the use-case defined in the series into, the following should be considered while evaluating technologies and resources:
- Highly scalability, which allows administrators to rapidly expand to meet new workload requirements. This could include onboarding additional data sources, running a higher volume of queries, performing more complex transformations and more.
- Highly modularity, which enables teams to rapidly and easily replace resources as newer capabilities are developed or released.
- High performance in terms of efficiency and cost, which provides low latency between the data source and detection at a low cost. .
Keeping these three qualities in mind as a litmus for individual decisions within the design, we seek to temper magic-bullet and catch all solutions that may back us into a corner and potentially elicit a receding hairline.
Handling API Calls
As with any challenge with minimal budget or resources issued by your executive leadership, and especially those that leads to multi-petabyte per day ingestion into a public cloud, you will run through all five stages of grief till you begin implementing. Naturally, you will defer to scaling out the technologies and methodologies with which you have the most experience, which will not always make the most sense at this scale.
In Example: If you have experience with virtual machines but are too busy to pick up Kubernetes or Docker, then you’re likely to take a stab at guessing the number of machines you will need, or build a Virtual Machine Scale Sets(VMSS). If you’ve written a lot of Bash or PowerShell scripts, then you’re probably going to stick to those over Python or Go.
There’s not anything inherently wrong with this approach or mindset, as the path of least resistance is often the key to victory in many deployments. However, if we use the 3-litmus points provided in the previous section against our examples, then the VMSS/Linux/Bash/PowerShell combination (as well as individually) starts to fall flat in the last category: being “high performance”, due to both low resource efficiency and cost.
Author’s Recommendation
We recommend that rather than wasting compute resources on virtualizing the kernel, sub-systems and services of your favorite linux distro in order to run a single script for API calls; that you instead consider containerizing said script and running through an Azure Kubernetes Services instance. For the script itself, we would recommend that it’s written Python, as it’s easily readable and a fairly common language in the IT Security community. Having said this, it may be advantageous to use Go for data sources which require more scaling or speed, as Go makes more efficient use of your resources at scale.
Data Ingestion
Microsoft Azure offers some amazing ingestion (or extraction) layer tools and services, though in most cases, it’s advisable for your data to pass through as few of these as possible in order to maximize the performance of the architecture and reduce unnecessary costs. As much as sales folks will try and push you into a Rube Goldberg machine, we suggest not being a rube and reducing the complexity and the multipliers at which you’re charged for the same data.
With this said, the first step with data ingestion is to independently evaluate the requirements for each data source you intend to land within your Azure storage account. This is probably the best time to start building a rudimentary data source matrix and ask yourself a lot of questions about logistics, such as: Does your data source need to touch Event Hubs or can a REST API be used to land the data directly into the chosen storage? Will the data source benefit from routing through an ExpressRoute, thereby justifying the increased cost? Typically, you can expect data source requirements to fall into one of the following three categories:
ExpressRoute & Event Hubs: Many data sources require the use of both Event Hubs and ExpressRoute, depending on the volume, structure and region where the data is generated. Typically, data sources that require Event Hubs are AMQP or Kafka event streaming types and sometimes (rarely) HTTPS. There are also many alternative options such as RabbitMQ and ActiveMQ which work nicely in similar scenarios, though these are not currently covered in the Azure SLA. In a post tandem to our Big Data SIEM with Azure series, we’ll provide a deep dive into optimized ExpressRoute & Event Hubs configuration.
ExpressRoute Only: SIEM teams typically seek to achieve near-real time analysis. Because of this, their workload with the majority of 3rd party data sources (and even first party data generated in a geographically separated region), will benefit from the speed of an Azure ExpressRoute connection straight into your environment. Examples of these data sources could include Zscaler, MISP, Fortinet and Per Call Measurement Data (PCMD) for our friends in the telecom industry — depending on how it is configured.
Direct Loading: Many data sources do not require the use of an ExpressRoute or Event Hubs resource, which could be for any numbers of reasons; though it’s typically because the data is ingested through a REST API or because the data source benefits from direct cloud-to-cloud ingestion, such as Microsoft Defender XDR, and Microsoft Defender for Endpoint or Microsoft Defender for Identity.
Author’s Recommendation
No one wants to get hung up in the opening phases of exploration or design work, but time spent here has a very high return on investment for the latter phases of your project. Some deliverables the management team could expect from this level of the ETL/ELT design phase include:
- An accurate Data Source Matrix
- Clear paths to implantation for each data source, with definition around potential bottlenecks and known unknowns
- A list of required ExpressRoute Private Endpoint, Virtual Network Service Endpoints, virtual networks, and the like.
We understand how tough it is to exercise discipline in this category while dealing with competing priorities and time constraints, but try to slow down and think through this step through carefully. You do not want to be on the implementation team who skimped in time investment or skipped this step of planning all together. Slow is smooth and smooth is fast.
Data Transforms & Enrichment
Though rare with datasets in this use-case, the need for limited transform and/or enrichment workloads can arise when the data source may be missing information important to your customers and their query workloads. The majority of the information are time critical log data and time series data streams, with a much smaller set being abstract or merged data.
When it comes to transformation, we would caution you to ensure that there is a clearly defined use-case or performance objective which justifies the compute expenditure. As an example, lets say that your leadership believes that a simple transform will save hours in query response time while running detections on the back end of the architecture. This may be the case, but you should keep in mind that even a simple transform or enrichment at this scale could require many millions of changes per minute (even with a single data source) which could make for a dataflow bottlenecks and/or a high compute cost when occurring ahead of the Load layer.
Having said this and if you decide to continue down this path, you and your team have some really good options:
- Azure Data Factory: Though it is often used as an ingestion tool (and for good reason), we would recommend that your ADF pipelines enrich data already present within your storage to prevent a bottleneck in data ingestion at this scale. Our main concern here is the volume of events per second(EPS) being ingested into the big data SIEM, as well as the throughput limitations of ADF at the time of this writing.
- Azure Databricks: A version of Databricks which has been “optimized” for the Azure cloud environment, the Azure Databricks workspace provides a unified interface and tooling for almost every data related task, including data processing in the ETL pipeline. Keep in mind however that as with ADF, leveraging this service within the ETL/ELT process will require personnel with specialized experience for the duration of the service use.
- Azure Container Apps: Depending on the complexity of your desired transformations and capabilities of the team, a simple Python or Go script could be run as a container image within Azure Container Apps or Azure Kubernetes Services. This can be implemented rapidly by most security engineers, though a fundamental understanding of data science workflows and strong grasp with the desired programming language of choice is also a requirement.
- AI Augmented Enrichment: We’ll cover this later in more detail, but as a preview: we recently developed a Machine Learning(ML) algorithm to sort and enrich structured, unstructured and semi-structured syslog data sources. As with the other data transformation & enrichment options, this option is best performed on the data at rest, rather than while it’s being ingested.
While most cloud based services have a massive (or unlimited) ability to scale horizontally in order to avoid throughput bottlenecks; remember to keep your budgetary constraints in mind. Even with clients who claimed that money was not a constraint (yes, we’ve heard this many times before): the solution will scale until your budget runs out.
Author’s Recommendation
Due to the volume of data and number of events per second, as well as the low complexity of the transformations typically required by the consumers of this data; our recommendation for an efficient transform process is to either change the data after it has been stored within the cloud, or run the transformation on-prem before ingested.
Loading & Storage
As briefly touched on within the Handling API Calls and Extraction sections above, the Loading aspect of our ETL/ELT pipeline is where the data is extracted by an API, Event Hubs or any other event streaming platform, then loaded into its storage service. Within our scenario, a common idea is to either send the extracted data straight to the detection service (which we’ve already recommended against in the series intro) or to fork the data from the API and/or the event streaming platform into multiple destinations (ie. ADX, ADLS & Microsoft Sentinel) in order to run detections in close to real-time and store the data simultaneously.
On the surface, it seems like a huge victory in latency reduction (from formulated event to detection query), but challenges with handling the data ingested by multiple sources will become a constant chore — not to mention the fact that you will be paying a premium to ingest the data into each detection layer service, only to throw it away after the query.
Author’s Recommendation
There are very few scenarios where loading ingested data into multiple storage containers or services (simultaneously) can benefit your ETL/ELT pipeline or the goals of The Big Data SIEM which it serves. We recommend consolidating the load layer to storage containers within a single service. These containers should be created to handle all needs of each individual data source, as well as the queries run by your detection layer services. In our next post (The Big Data SIEM — Storage in Azure) we’ll provide specific recommendations on storage types and configuration for queries and detections.
Implementation:

It’s said that every plan survives until first contact with the enemy — and building in the public cloud is no exception. Make no mistake: You will run into technical blockers and bottlenecks along the way, but with the right team composition and organizational alignment, these can be minor speed bumps on the way to a successful deployment.
Team Composition:
The below recommendations are our go-to resource model for delivery of the ETL pipeline portion of this use-case, as well as much of the delivery of the public cloud-based SIEM. Though everyone has their own role, each team member must have a strong technical background (you too PM’s!) accompanied by working knowledge of project delivery.
- Sr. Technical Lead: The Technical Lead is overall responsible for the design and performance of the architecture. Success in this role requires in-depth technical expertise, understanding of service shortcomings and working knowledge of the business use-case implications for a design change. The Tech Lead should also be able to quickly develop proof-of-concept(POC) models which explore direction changes requested by the client, while also serving as a point of escalation to the greater project team.
- TPM: The Technical Project Manager (or TPM) plays a pivotal role in the overall delivery effort. Not only should they have a solid background in project planning, administrative function and day-to-day management, but they should also serve as a point of escalation for basic technical challenges as they arise. Of critical importance is their ability to interface with other data customers, provide backup to the DM during status meetings with the executive team, and manage burnout of the greater delivery team.
- DevOps: Regardless of individual member’s programming background and capabilities, no delivery team is complete without at least one designated DevOps professional who is solely focused on programming tasks. Ideally, this team member will enable your architects/Sr. Technical personnel to focus on implementation of core services and resources by themselves focusing on custom data source connectors, containerized applications, scheduled KQL queries and much much more. Trust us when we say: A skilled DevOps professional will make implementation much smoother.
- Security Engineer / SME: The ideal Security Engineer has 5+ years of experience on security or implementation teams, and can be entrusted by the TPM, Sr. Technical Lead and to “own” an entire series of master tasks (with associated sub-tasking) or work-streams. This team member must have working knowledge of multiple workflows within a security context.
Regardless, with 6–8 personnel allocated in the above team composition, you should be able implement the ingestion layer of The Big Data SIEM and handle any curve ball thrown your way.
Organizational Alignment
Despite its apparent complexity, an ETL/ELT pipeline which is optimized for your modern SIEM can be designed and built into an effective project plan (complete with a KPI schedule) in 2–3 weeks. However, it should be noted that some focused time investment is required from the various customers of the data.
In nearly all cases where we’ve seen earnest department head alignment and sponsorship (or “buy in”), the project planning process was streamlined to just hours of planned meetings, followed by a few days of back and forth via email and calls. This will generally yield concrete project plans with unified metrics for success. Unfortunately, we’ve also been a part of projects where the opposite was the case, which generally only serves to burn up precious time and lead to higher stress. In the latter scenario, an honest analogy we’ve used has been “building the car while driving in it, at 100mph”, as newly discovered customer requirements lead to major overhauls to the core architecture.

Regardless of your years experience, you should not make assumptions about the requirements of the various departments or needs of the customers. Ask for them to define their needs, wants and “reach” goals early in the design process, and work to justify their sponsorship within key workflows.
Implementation Timeline
Assuming that the above recommendations are followed , we estimate that it would take roughly 4 weeks to implement the ingestion layer for the “big data SIEM” in Azure. This is complete with, documentation, data source matrix, security hardening audits; bringing the combined (planning & implementation) for the ingestion layer to roughly 6 weeks.
Conclusion & Further Reading
As we continue digging into the individual layers and expand on the design including best practices we hope that it inspires you to implement portions of the design within your own environment as these principles are modular, however following our recommendations will help you avoid rework and excessive expense.
In the next post, we’ll dive into the storage layer and make some detailed recommendations on the technologies, their configurations and provide guidance on Data Life-Cycle Management(DLM) as it may benefit your architecture’s compute and fiscal performance. We’ll also touch on how to design and use the storage layer with queries from the detection layer keeping the end users and stakeholders in mind.
Please reach out if you have questions or wish to see more information on various points of what we have written on. If you’d like us to focus on certain areas that may help your unique situation please comment or reach out to Tyler G. (Tyler G. LinkedIn) or Tyson Barber (Tyson B. LinkedIn).