Back in June 2024, I wrote a post about a homelab project I had started, which aimed to characterize the dark web. The project was ultimately a success, achieving an average of ~75k .onion v3 resources located (verified & enriched) per 24 hours, over a 6 day “final” trial period. This was roughly 10x the speed of similar projects I had found while preparing for the project. However, I decided to discontinue the project in late July for a number of reasons — namely, because another homelab project stole my interest (security focused LLMs). Despite what my colleague Tyson Barber will tell you: There is in fact only one of me, neither of which is actually a machine.

Additionally and due to the performance and the ease at which any type of content could be discovered, I’ve decided not to publish the full source code, but will release the main script and several of its modules to a newly formed github repository.
As this post is mainly about knowledge sharing, I also will share an updated version of my methodology, approach and project architecture, some failure points and the direction it was heading when I pulled the plug. If taking on a project of this nature is interesting to you, I hope that this provides a pretty good starting point.
The Secret Sauce
Don’t want to read this post? I get it, so I’m giving you the ‘secret sauce’ in bullet points up front. The following are key bullet points which I believe were key to the project’s performance:
- Approach and Workflow Optimization
- Asynchronous processing of data in batches, through the concurrent.futures library
- Run on 24 thread CPU (set to 12 in repo)
- Bare-minimum scripts for each process or step, executed as modules
- Containerization (not tested)
Disclaimer
This project only builds and populates a MariaDB SQL database with metadata tags created during the enrichment process, solely for the purpose of characterizing and fingerprinting .onion URLs. As it was designed to augment OSINT or threat intelligence investigations, it does not at any point collect or store written content, imagery, videos or gifs.
Background & Approach
For context and given the approach we’re about to walk through, it’s probably worth mentioning that I have a fairly deep background in OSINT & Targeting, and that I’ve spent much of my free time working through HackTheBox, TryHackMe and the OSCP. Further, I’ve been an active member in numerous online security research communities, such as Black Hills Infosec, TCM Security and others, for the better part of a decade.
Professionally, I’ve been working in client-facing security & infrastructure engineering roles for roughly 12 years, where I’ve been fortunate to experience the fusion of big data challenges (as seen in The Big Data SIEM series) with many lessons learned in the aforementioned communities and training series.
In both aspects of my life, I try to approach every project with an open mind and no assumptions, then move to develop a deeper understanding of “why are things this way?” Sometimes this pays out, sometimes I add a foe to the roster.
Regardless, it is worth admitting that I do not have any formal DevOps background…..as you will probably guess by looking at my code.
Design Approach
As I was viewing the code for many of the higher performing dark web crawlers published to Github and elsewhere; I noticed that for the most part, their designs followed a monolithic scripting approach in which a single loop would ping a known site then proceed with enrichment tasks (sometimes) until all desired data data was gathered. Generally, they would commit to a storage of some sort then rinse and repeat. Further, they often used a combination of white & black lists, likely in alignment with the developer’s moral system.
Rather than follow suit, my project design is akin to the ETL process deployed for big data targeting. Instead of pinging one address at a time, data is handled in small batches, walking through the medallion architecture for enrichment of the metadata fields included. Rather than leveraging white & black lists as filters, my process would collect everything and sort it out in the tail end with a parallel workflow. This makes code execution more performant and avoids making any assumptions about the end consumers use-case. Toward the end, custom workloads are deployed to add definition around key (or targeted) .onion resources which meet the criteria of the workload itself. Where user profiles are discovered, an automated queue is built and eventually triggered to search breach data collections for additional pivot points if needed.
Additionally, I had planned to run the system in a hub & spoke style architecture across multiple geographically dispersed virtual private servers(VPS) via Kubernetes(k3s). Because of this, this project was designed from the group up to be modular, with many phases of indexing, enrichment, data processing/cleaning and custom workloads running in parallel. After staging refined data on the VPS device, a scheduled export to a ‘master’ database would execute, thereby consolidating all records. Many of the custom workloads would be performed here, as they are heavier in compute requirements.
Basic Workflows
There are three basic workflows to this system. The first two build, enrich and maintain data within the SQL database, while the final category of workflows are created to build further definition around the resources location, their users, and the like.
I will point to specific code samples published to the projects Github repository, but this section seeks only to provide a high-level overview of each phase. Remember that this is only a partial release with many steps in between and after.
Resource Discovery Workflow
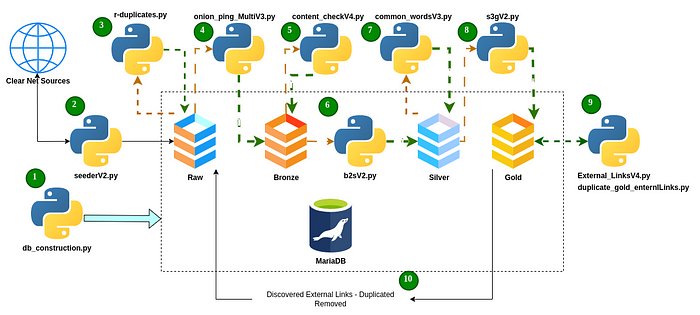
The project’s primary data discovery & enrichment processes (D&E Github Repo) occur within this section. While there are some additional steps and code snippets in between, here is the general workflow which populates and enriches data on V3 .onion resources:
- Seeding: The seeding process leverages open source databases to collect sites which have already been identified by indexing services. The seederV2 module references a local .txt file to form structured search queries into ahmia.fi and some others, but only after the SQL database has been created and its tables defined by the setup process. Results are copied into the Raw table, where redundancies are removed prior to each row continuing its enrichment journey. During testing, I used a list of just over 200 words, which returned roughly 28,000 results. Removing redundancies culled this number to less than 4,000 unique sites Additionally, ahmia.fi only returned sites: never chat rooms, file shares or file repositories.
- Verifying Onion Service Status: Within the Raw table, URLs are pinged for the service status code. URL’s which return 100, 200 and 300 status codes are moved to Bronze table and start their enrichment journey, while those returning 400 & 500 type status are sent to the Removed table. This is performed with the Onion_PIng_MultiV3 module.
- Content discovery: Each resource is examined for content (imagery & text) which are represented in the table by a binary value. Oddly enough, this detection ran me into another challenge, which I sought to address fingerprinting/URL classification capabilities addressed in another section.
- Common Word Collection: This is performed by the common_wordsv3 module, which tokenizes every word present on the URL visited, then calculate the X most common words to the row — where X represents the user-defined number of common words they would like to extract. This will automatically exclude “stop words” such as ‘the’, ‘like’ or ‘and’, but will include words such as ‘Buy’, ‘Untraceable’, ‘Gift’, ‘Cards’ and ‘Crypto’.
- External Site Discovery: This is where the true link analysis will start to take place, in that X number of external URLs are collected and added to the source URLs row. This feature was created not only to harvest additional .onion URLs, but also for later use as an export into a Graphical database such as Neo4j. With this ability, researchers might identify traffic bottlenecks from the index page to your ultimate targeted resource.
- Onion Resource Identification: This module (not for release) was created to characterize status 200 sites which returned zero’s for content, imagery, common words etc. This issue actually reminded me of a post I wrote in the past on Onion Share, which enables any low-tech user to rapidly set up and run one of four types of resources on the dark web: Websites, File Shares, File Repositories, and Chat rooms. Though the majority of these will have a short life-span (relative to many sites), it is a useful fingerprint mechanism.
- From Gold to Raw, then Cleaned: All external or associated sites discovered during the enrichment process are added and copied from the Gold table to the Raw table, where they will be treated as their own URL for enrichment. Prior to this, however, all redundant domains are removed from both the Gold and Raw tables so that only one copy of each URL exists. This was created because during early testing, I found numerous “computing traps” in which tens of thousands of URLs would lead the crawler into an infinite loop within a single URL. I actually love little traps like this, so my hat is off to whoever put this together — if they did it intentionally.
Though this workflow is performed in a continuous loop, each iteration appends clean, unique entries to the Gold table. Even if this workflow was the only performed with 12 threads (12 workers) continuously for 24–48 hours, you would likely have enough data to begin a legitimate excursion into the dark web.
Administrative & Upkeep Tasks
Beyond enrichment, special care was taken to ensure that the data harvested was relevant and up to date. Unfortunately and likely due to the complexity of the dark web, this is a shortcoming with most projects and indexes in this field of research.
- Re-Ping Status 400 Sites: If a .onion URL has previously returned a series 400 status code, it’s saved to the Removed table where it is pinged several times per day for the next 45 days. The URL returns a status 200, then it is added to the Bronze table and continues through the above process during the next sweep.
- Re-Ping Status 200 Sites: As one of the goals of the project is to maintain an updated inventory of active onion resources, all active sites listed within the Gold table are re-pinged daily.
Tailored Workloads

Specialized workloads are created to build further definition from the rows within the Gold database, tailored to a specific area of interest. For example: Say you were performing an investigation into how much your organization is being specifically targeted by access brokers within known dark web forums, which users seemed interested and how their username on the forum might make contact with the clear web.
The Tailored Workload template could be modified to constantly query your Gold database for terms, users and crime organizations.
- Automated Gold table queries
- JSON file developed, enriched and tagged based on findings
- Username and group cache, enriched and tagged
- Automated pivot with usernames to breach data
Table Schema
As depicted, articulated and beaten into the ground by this point: I sought to mimic the medallion architecture which would handle the data in batches.
- Raw Table — Seed and Unverified: 7 Columns
- Removed Table — 400 Status Codes: 7 Columns
- Bronze Table — 200 Status code from Raw: 12 Columns
- Silver Table — Enriched with top 5 keywords: 18 Columns
- Gold Table — Enriched with External Links and progress status: 45 Columns
I did share the SQL (MariaDB) table construction script for this project, within the “setup” folder. If you would like to see the specific fields this project populates, check out the db_construction module.
What It Found
Believe it or not, I only visited a handful of sites during this project’s development which were selected at random to test the accuracy of the data collected. Of these were index sites, forums, and the .onion mirror of a mainstream news outlet. Sifting through the Gold table in the SQL database, I saw tags for everything from anime forums in Russian, self-hosted blogs on Cuban democratic political movements in Spanish and even an Etsy-styled marketplace for trinkets a guy was making on his farm. I also found drugs, obvious money laundering services (and money mule recruitment) and more.
Unfortunately, there were also metadata tags for unspeakable evils…..really awful stuff. This is the reason that many use white list / black list filters, and why I’ve decided not to publish the full project code. If you work in law enforcement or with a non-profit / research group, I would be happy to speak with you.
Partially Complete
There were a couple of additional capabilities in development which would have been included had I decided to press on with the project. These are simple enough to build, but I’ve decided against sharing them for now.
- API’s Access & Crawling online forums: I could not locate the article at the time of this writing, but read that 90% of Dark Web users had sourced links from clear net sites, forums and chat rooms. After finding this, I started the construction of a peripheral ETL pipeline, designed to actively pull URLs matching the v3 .onion URL syntax into a separate table, prior to joining the enrichment process.
- Crawling I2P: Admittedly, this is only about 30–40% complete, but I was working to build a similar series of capabilities to crawl the Invisible Internet Project(I2P). These were designed work in different database with similar tables
Closing Thoughts
This was an exciting project and though I have decided to discontinue it for now, I was able to pivot with a lot of lessons learned to a new homelab project: A new JARM project, which I hope to finish in the Spring of 2025. Written in Go (my new favorite), this project will build upon the capabilities of the Salesforce JARM tool merged with an improved version of data enrichment and management as seen with this project.
Regardless, I hope that this project adds some value or inspiration to my fellow dark web researchers. I’ve closed comments for this post but hope that you will feel free to reach me via LinkedIn if you have any comments or questions — and that I’ll be able to share more about the new JARM project soon.