
Though most Large Language Models(LLM) feature strong out-of-the-box capabilities with a wide spectrum of knowledge, they often fall short when asked to perform in-depth tasks within a specific subject matter — making them less that useful within specialized domains, like cyber security. There are two basic options to remedy this shortcoming while mitigating sacrifice of natural language processing, language generation and coding or scripting: Fine-Tuning and Retrieval Augmented Generation(RAG).
For this project, my goal was to create a utility which could augment the blue, red and purple team member through their daily tasking. Low-Rank Adaptation(LoRA) Fine-Tuning was performed with a large personal corpus of books, manuals, course materials and other materials scraped from online forums. Featuring nearly 400 separate documents, this will (ideally) serve to enhance the core model’s out-of-the-box capabilities (Mistral 7B) with tailored knowledge from the security domain.
As the model was training within my homelab environment for several days, I used another machine to build a custom Extract, Transform, Load(ETL) process, designed to feed and update the vector database used by the RAG process. The code for both of these can be found on its Github repository (coming soon), and it is recommended that the ETL process be executed on a chron job every few hours in the background.
Disclaimer
This post is a general overview of the process behind how “I built a thing”, and will provide only a high level summary of each concept discussed. All code samples will be available on the projects Github repository (coming soon). If you would like to download and play around with the model, you can do so at the models huggingface repository page. I’ve disabled comments for this post, but would be happy to connect and chat on LinkedIn.
At the time of this writing, the model has finished its 4th training epoch, with a validation loss of 1.601, but I have not tested the final epoch— which is the reason that its release to hugging face might trail this article by several hours. To be honest, I have only trained a handful of Low Rank Adaptation(LoRA) models, with most of my work being in Autoencoder, Recurrent and (more recently) Convolutional Neural Networks, and the majority of my LLM work being in “Full Fine-Tuning”.
The Concept
As I mentioned the red, blue, purple security teams above, I wanted to create a utility to augment their efforts in known system, server, network, cloud and other vulnerabilities on the blue team side, while supporting testing (and possibly development) of novel threats for the red team. The main theory here is to raise the model’s aptitude of security topics, then attach it to a RAG full of CVE and other data sources with TTPs, indicators of compromise and more.
I’m planning to support and update components of this project for a while, but this version of the model is best thought of as the “alpha release”, as it was designed to be a experiment and control against the more in-depth, more complete version I’m planning to develop in the immediate future. For the current version, I wanted to test the LLM’s abilities after applying Low-Rank Adaptation(LoRA) to 16 of 32 transformer blocks present in Mistral 7B, which would then work with the Retrieval Augmented Generation(RAG) pipeline.
The challenge here is that while 16 LoRA layers may be enough to adapt tone or enhance task behavior and instruction following a small dataset, applying LoRA to all 32 transformer blocks will capture more complex behavior and better align the full transformer stack to the dataset. In the end, I’ll likely release several versions of the 16 layer version as I work to enhance its performance, with fewer 32 layer versions.
So why didn’t I just start by training the full 32 transformer blocks instead of just 16? Aside from the obvious reason that applying just 16 LoRA layers makes for faster experimentation and/or trial & error (and there is plenty of that), and that I’m building this within the limited resources of my personal homelab; I wanted a side-by-side comparison of both models, using the same data and the same RAG for my own knowledge and bench-marking. If I find and receive feedback that the 16 layer model with the RAG performed nearly as well as (or better) the 32 layer model with the same RAG, then I can stick with the more economical 16 layer training pipeline and push changes more rapidly in the future.
The Complete System Architecture
At its highest level, this project was designed to continuously ingest CVE and other threat data into the vector database, enabling the Retrieval Augmented Generation(RAG) capability with the most up to date data. Below, this is represented by LLM embedding, the vector database itself and augmented query.
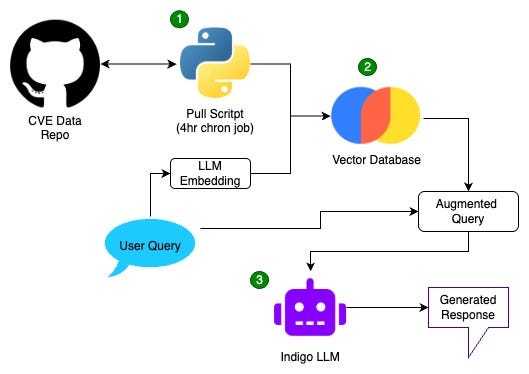
The Pull Script (1) above compares the records from the CVE List V5 Github Repository to those already present within your chosen storage. If new data discovered, the script downloads the new records, transforms and loads them into (2) the vector database. Ideally, this process is performed every 4 hours in the background to ensure that the most recent data is present while augmented queries are being generated.
We’ll go into the details for Retrieval Augmented Generation(RAG) in an upcoming post, but for now, notice how the user query is filtered through LLM Embedding and the Vector Database, then joined back at Augmented Query, rather than interacting directly with the LLM (3).
Development Process
When developing a project like this, focus is broken into 3 primary areas, to include: Building the Core Training Dataset, Building the ETL scripts feeding the vector database and the training process itself. Since I had the training process fairly dialed-in from previous projects, my main focus was on developing python modules to transform data from its original PDF format to its ultimate form in JOSNL.
Building the Core Training Dataset

The first step was to prepare documents which cover a wide spectrum of cyber security topics, to include programming in numerous programming languages, penetration testing, ERP, CIRT, DFIR, OSINT, Malware Forensics, Database administration and security, cloud security, Threat Hunting, API Security and much much more. Luckily, I have been collecting these for nearly a decade, but I was able to obtain several additional works for this project from fellow data hoarders. In total, this collection included nearly 400 books, ebooks, manuals and course materials in PDF form, from which the text was extracted and placed in a .TXT file, one file per page, with over 350,000 pages produced in total. Also in the collection were a series of clippings, guides, forum responses and code samples I found useful over the years.
In order to transform these files into a dataset which could be used to perform LoRA Fine-Tuning, I developed a series of modules (represented by the python logos above) to clean the collection, redacting information and pages which are not useful to the training process. Think of those files removed as the pages of the book that you are likely to skip reading (About the Author, Preface, Index, Table of Contents, blank pages, etc..) while going through a technical manual or novel, because you know that it will not appear on a test.
The last step for the data in .TXT form is to break each files into a length that can be loaded by the memory of your GPU memory during training. To do this, we import the models native tokenizer into a simple python script and have it iterate through our directory to split the files accordingly. As mentioned above: I chose to train 16 LoRA layers (transformer blocks) in batches of 2, so I know that 2048 tokens per training set will make for stable training operations given my machines resources.
The JSONL Files
The JSONL (JSON Lines) format is often used for LoRA fine-tuning because it strikes a perfect balance between simplicity, efficiency, and compatibility with most training pipelines. As you can see in the example below: each line is a self-contained JSON object containing the full volume of text, which can be loaded one at a time or in batches.

In my training pipeline, each JSONL line represents a 2048 token training sample (produced with the Mistral tokenizer), of which there were roughly 198,000 lines in total. As shown in the diagram above, the lines in the final JSONL file are shuffled to produce the ‘Main JSONL file’. This is because as the model is training, it updates its weights based on min-batches of training data. If the batches of training data cover homogeneous topics, use of language, phrasing and the like, you’ll end up with correlated gradients which slow convergence and can lead to inferior model performance.
So to avoid this, the data is shuffled within the Main JSONL file, then is split into three smaller JSONL files (train/validation/test) for even cleaner separation and more realistic evaluation.
Training Process
A training epoch is one pass through all training samples within the ‘train’ JSONL file. At the beginning of the first epoch, the validation loss was 2.375 but finished at 1.857. By the end of the fourth epoch, validation loss was was 1.601, which is a solid drop for LoRA fine-tuning, but I have not yet achieved my goal of a val loss of 1.50. I’ll admit that this is fairly ambitious for 16 LoRA layer fine-tuning, but I believe that it’s achievable with the right process, variation in data and training dataset structure.
Challenges to Development
This probably isn’t what you’re expecting, but the biggest challenge I faced during development was that the GPU’s in my homelab burned out part way through the 2nd training epoch. I have had limited time to troubleshoot these so far, but they seemed to be operating at less than 40% of their face-plate capacity, dropping the combined capability below the threshold needed for effective LoRA fine-tuning. We had a good run and there’s no telling how many weeks of continuous run time at 80–90% capacity I got out of them (totally worth 2023 NVIDIA prices), but they failed me after I told a friend (Tyson Barber) “I should have this LLM up in about a week”.
After mentally accepting that I was going to have to throw money at Google Cloud Platform(GCP) I decided to finally give Apple’s MLX a try on my wife’s Mac Book Pro M4 with 16GB unified memory. In a few hours, I was able to make some major modifications to my workflow training scripts and get the MLX Framework running on Apple Silicon — and readers, I was impressed enough to buy a Mac Mini M4 Pro with 64GB unified memory rather than multiple NVIDIA 5090s.
I’m “new toy” excited to test both Apple Silicon and MLX with other deep learning workloads, so stay tuned for more posts on this topic.
Future Development
The next step for this project is to clean up and comment the python utilities I created, then publish and article on the RAG. For the model itself, I would like to is push the LoRA fine-tuning into the 5th, 6th and possibly 7th training epoch to see where the validation loss starts to plateau for this dataset. Once it does, I’ll work to clean the dataset, append more information and start lining up my workflow for a full fine-tuning operation with GCP. As mentioned above, I would like to get down to a val loss of 1.5 for LoRA on my Mac Mini, but we’ll see.
Unfortunately, and since these are all projects for my off hours, I may need to take a break from the Indigo LLM project to build the tooling needed to prepare the dataset and train a Convolutional Neural Network(CNN) that I’ve been designing. Fortunately, all tooling for Indigo is already streamlined into a point-and-shoot solution, so I should be able pick it up quickly when I’m able to continue research.
Conclusion
I hope that you enjoyed this article and that you’ll take the LLM for a spin. If you ran into unfamiliar concepts or the hyperlinks provided did not help as much as you had hoped, don’t worry: I’m in the process of building a series to teach you how to fine-tune your own LLM’s in your homelab. Through these, we’ll be diving deeper into each topic with practical examples.
Thanks for checking out this article and again, I would greatly appreciate your feedback on the models ( https://huggingface.co/TylerG01/Indigo-v0.1 ) performance within your security workflow via my LinkedIn.