

Retrieval Augmented Generation(RAG) is the method of choice for increasing the output accuracy of Natural Language Processing(NLP), generation-based models. I’m not claiming that this will eliminate your generative model’s chances to hallucinate (as some do), but it does push the the model to retrieve relevant documents or pieces of information from your own corpus, based on the user’s query.
Once the relevant information has been retrieved, the generative model leverages the information to generate a coherent response, within context of both the (a) information within your tailored corpus and (b) within the context of your query.
As mentioned in my previous post, Indigo LLM is one component of a larger architecture, designed to help blue, red and purple team operators during their daily engagements. In this post, we’ll complete the architecture with scripts to perform the Extract, Transform, Load(ETL) pipeline which feeds the vector database with new information from various threat research databases. While this post will focus on CVE data as an example, the scripts provided can be modified to pull from any data sources that you like.
I always try to build my homelab projects to scale to enterprise use cases; as such, this model can be replicated and deployed ‘as is’ within a enterprise cloud environment.
Use Case
There are a plethora of use cases for using Retrieval Augmented Generation(RAG) within a LLM workflow, but for my personal and professional use cases, I like to use RAG in three primary ways.
First and most obvious is to improve factual accuracy within a specified domain, when and if provided with grounded external information. Since RAG retrieves relevant documents from the vector database to guide the LLM, it reduces reliance on information stored within the LLM’s memory alone.
Second and as is a key element within the Indigo LLM project: A solid RAG workflow enables the user (and model) to access knowledge which is both up-to-date and custom in nature. Because of this, RAG can serve as a buffer which enables more time to pass before the core LLM must be retrained to incorporate new data. You can simply focus on the quality of the data being input into the vector database.
Third and finally: RAG extends the power of smaller models, by giving them access to the contextual information discussed above. This grants us the ability to pair lightweight models (such as Mistral 7B or Indigo LLM) with high-quality data retrieval, enabling the smaller model to outperform large models (such as Llama 4 Behemoth 2T) within domain specific tasks, such as cyber security, healthcare, legal and more. If planning to use RAG with your LLM workflow, this point enables you fine-tune and maintain LLM’s which are significantly smaller, requiring far fewer resources (in terms of funding and compute) during the training process.
Disclaimers
There are a lot of great vector databases out there but my go-to’s are FAISS and ChromaDB, the latter being the logo that I used in the architectural drawing below. While both have many of the features needed for this workflow (such as python libraries for vector search, LangChain integration and massive scale), I’m reading more and more that FAISS works better in production scale searches and with billion-scale apps due to its GPU indexing ability.
ChromaDB on the other hand, may be more ideal for local small-to-medium sized RAG deployments, as well as small-scale projects deployed within environments with more hardware and memory constraints. If you are following along and deploying Indigo LLM with the RAG architecture on a laptop (totally possible), and only the CVE data is being ingested: I would consider ChromaDB for your vector database. If deploying to a cloud or a workstation with large GPU(s) installed, and you plan to use multiple data sources, give FIASS a peek.
Additionally, there are several scripts and code samples which I am in the process of commenting and cleaning up. This post will be updated with the projects github repository as soon as these are complete – I will not leave you hanging.
Last but not least: I’ve disabled comments for this post, but would be happy to connect through my LinkedIn account.
Retrieval Augmented Generation(RAG) Architecture
As discussed in the previous post, the specific use case with Indigo LLM requires that our vector database be periodically updated with the newest CVE data. Within the below diagram, you can see that I’ve set a cron job to execute the ETL script in the background. This is because I assume that the machine, VM or container this is running on will have resources to spare. If this is not the case for you, another option could be to execute the ETL script prior to use, similar to any tool you would use during a red team engagement.
The full RAG architecture for this project, looks something like this:
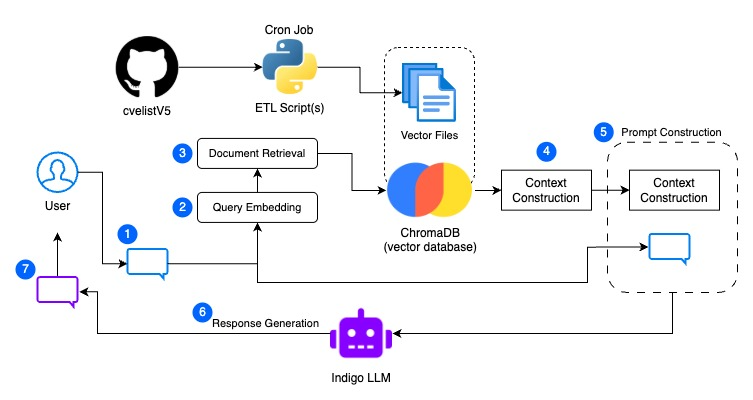
In the above diagram, you’ll notice some familiar components mixed in with the RAG process. Excluding the ETL process for now, Retrieval Augmented Generation works in the follow seven basic steps:
- Input Query: The user submits a natural language question or prompt, just as you would with any LLM.
- Query Embedding: The input query is converted into a dense vector using an embedding model, such as SentenceTransformers or OpenAI.
- Document Retrieval: The system performs a vector similarity search over the pre-built vector store (ex FAISS or ChromaDB). The top-k most relevant chunks matching the pastern of the query.
- Context Construction: The retrieved documents are concatenated into a single context window, which is formatted and pre-processed for input into the Large Language Model(LLM), such as Indigo LLM.
- Prompt Construction: The original input query and the formatted output from context construction are fed to the LLM.
- Response Generation: The LLM takes the constructed prompt and generates a ground response, using the retrieved context to inform its answer.
- Output to User: The generated answer to the original input query is returned to the user, though with more context-aware response than that which is produced by the LLM on its own.
As the entirety of this process is handled in the back-end, the user will notice only a small difference in performance compared to interacting with web UI models (in that the local or enterprise cloud deployed model is much faster) and in that the accuracy of the response is much more accurate.
Breaking down the ETL Process
A core component of the RAG workflow is the automated ETL pipeline. As it was intentionally left without numbers above, lets break out this component of the architecture, which is represented by a GitHub, Python and File logos within the full architecture diagram show above.
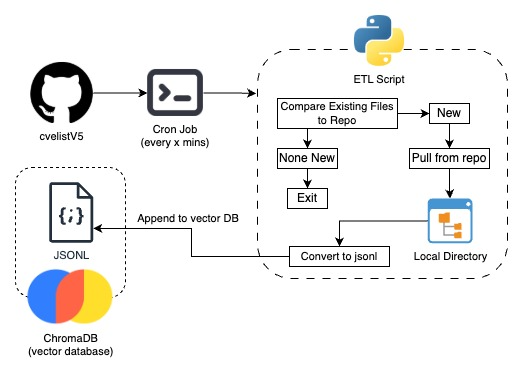
At the core, a simple ETL Script features a series of python modules which compare json files currently within a local file directory, to those existing on the cvelistV5 GitHub repository at the time the script is executed. According to the documentation (which I know people never read) the repository is “updated regularly (about every 7 minutes) using the official CVE Services API”. You could execute the ETL process every 7 minutes if you wanted to, but my cron job was set to execute this script once per hour and I wasn’t catching a ton of record changes in my log output files.
An easier and just as a effective method (possibly more effective) for those of you whom plan to extract only data from the CVE repository would be to just delete all files in the Local Directory with the Cron Job, then Execute an ETL script which no longer compares existing files, but still pulls in and converts new files into jsonl. Why more effective? Well, as the compare function is written right now, it would use more compute attempting to compare every json file within the local directory than its worth. However, the ETL pipeline shown was designed with the assumption that the admin would scale to numerous data sources, both internal and open-source.
In the latter scenario, comparing records is much less bandwidth and compute intensive (especially when executing multiple times per hour) than extracting, transforming and loading a large volume of records from multiple sources.
Is Fine-Tuning an LLM Irrelevant?
At this point, some of my readers are probably asking “So, is Fine-tuning irrelevant if we’re just going to use Retrieval Augmented Generation(RAG) in the LLM’s architecture?” My answer is that it’s not so black and white.
Fine-tuning teaches the model new patterns, styles and behaviors permanently by modifying weights during the training process. It is slow and resource intensive to train a model, but it’s great for reasoning improvement and teaching new tasks, which ultimately changes the way in which it works with the date within your RAG.
On the other hand, Retrieval Augmented Generation(RAG) is much less resource intensive and is great for rapid domain grounding or semi-effortless knowledge injection. As shown above, an example of this could be adding the most recent CVE data (just a few minutes old) to your vector database, enabling your model’s response with new data.
So the best practice as of right now is to do both: Fine-tune the LLM for chain-of-though reasoning, generating answers in certain tones and enhancing memory – then use RAG to generate responses with up-to-date facts and content. Though this was my thinking for Indigo LLM, I wasn’t quite able to get the model’s chain-of-thought or reasoning where I wanted it to be with v0.1. After significant changes to the core data set however, I’m optimistic about the current version (v0.2) which I’m planning to release to my huggingface account on the week of April 27, 2025 or the week of May 4, 2025.
Conclusion
As discussed above, a simple Retrieval Augmented Generation(RAG) workflow is a great way to augment generative AI responses, especially when working within a specific domain and with rapidly changing or expanding information. I’m excited to demo Indigo LLM v0.2 + the RAG process shown above for everyone, and hope that you will tune in for my upcoming posts on Google Vertex and Apple’s MLX framework for LoRA Fine-tuning your own LLMs.
A very special thanks to Tyson Barber for proof reading, sound boarding and sanity checks a long the way. Thanks also to everyone who has engaged, shared and commented on my work via my LinkedIn. I’m happy to connect there and you are free to reach out to if ever you have any questions.