
About a year ago, I read an article about a South Korean research group that built an LLM (DarkBERT), trained on Dark Web data. To be honest, the concept as well as the its technological and process challenges had immediately piqued my interest.
At a high level, DarkBERT uses a self-attention mechanism to process input within it’s transformer architecture. Regardless of this, the group would first have to start with (a) indexing links then (b) cataloging their content before finally (c) scraping the data. However, due to the privacy and security of the Tor Network, there are many challenges associated with indexing and scraping websites and services.
While this project uses Python, MariaDB and other technologies (due to their ease of use), its goal to conduct an experiment with which I hope to discover an effective process for building an index of hidden sites and services. Worded Differently: The process (not the code) is the project.
Disclaimer
This project and its capabilities are intended for ethical research purposes only. The author does not endorse utilizing the project to view, source or otherwise obtain illicit, illegal or other materials and content which may harm life in any form.
On Collecting Tor Addresses
Its well known that the Tor network offers users a high level of anonymity and privacy. As discusses in a previous post, v3 onion addresses consists of a set of randomly generated addresses, 56 characters long with base32-encoded characters, which adds complexity to the challenge of discovering, collecting and maintaining database of active sites.
While recent surveys indicate that the majority of its users access the Tor network for private communications, the anonymity offered to resource administrators and clients side users alike is inherently attractive to criminals, traffickers, terrorists and those engaged in illegal activities of many types.
Unfortunately, the illegal/harmful user-base has driven many projects (especially those with publicly searchable databases) to limit the breadth of their search and indexing abilities, rendering their engines less than useful to OSINT analysts, researchers, law enforcement and others concerned with characterizing the ecosystem of resources present on the Tor network for legal and ethical purposes.
Within this topic, it’s important to note the a core objective of this project is to discover, characterize and eventually classify as many sites and resources as possible. As you can see in the source code, no images or media files will be downloaded to the host environment, but I’ve not placed any controls to restrict discovery of harmful or illegal resources – as this may be useful to some researchers.
Discovery of Additional Services
Services which utilize the Tor network, such as SSH, FTP, chats, email and botnets, are less likely to be discovered by web crawling techniques, which rely heavily on following links located on previously crawled (or seeded) sites,to pivot to new sites and resources.
At the time of this writing, I am testing 3 main methods to discover chats and email addresses, but the SSH, FTP and botnets would require significant additional research.
The Process
At the highest level, the process has three basic layers: Seeding, Data Enlightenment and Serve Layers. The Database and Table structure is designed to emulate the Medallion Architecture which is frequently employed in enterprise environments to create reliable and organized data. Each table name is reflective of the quality and refinement of the data within:
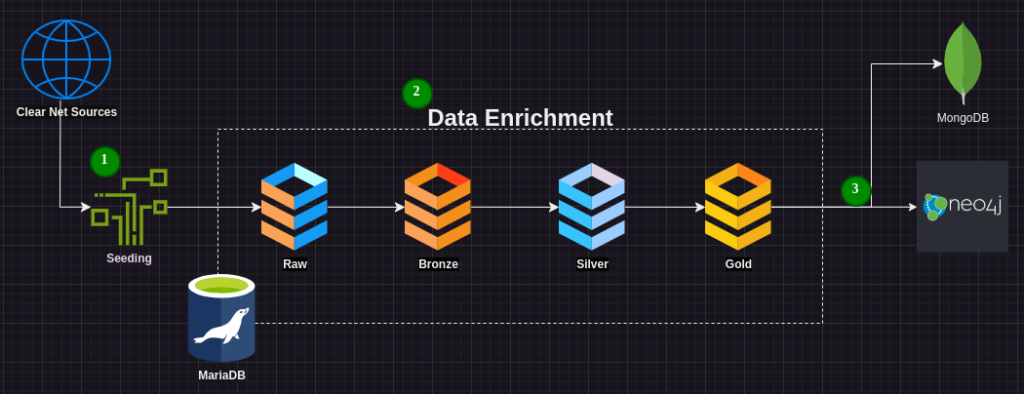
1. Seeding & Ingestion
Seeding is the process of rapidly collecting large volumes of known URLs. This benefits greatly (some would call it “piggy backing”) from open sources and other projects which have done much of the heavy lifting in discovery. However, I have often found that the majority of links sources from the large indexing projects do not represent active sites.
This was validated during numerous trail runs with the Onion_Scraper, producing duplicate sites at an average of roughly 65%, only about 70-80% of the remainder of which were active URLs. This means that once duplicates were removed, only about 24.5% of the sites obtained during the seeing process were active.
2. Data Enrichment
The middle phase of this process is concerned with validating URL’s discovered during the seeding process. Represented by the Raw, Bronze, Silver and Gold tables within the MariaDB database depicted above, an active URL moves through each table (each adding descriptive data) until it reaches the final form in the Gold Table.
This data will include the top descriptive key words appearing on each site, up to 50 external links located on the site, whether or not the site hosts images, and much more.
3. Serve Layer
From the Gold table, the data can be exported into JSON files (stored in MongoDB) where it will be further enriched, and into an Neo4j database, where traffic analysis can be conducted.
Use-Cases
My personal goal is to build a series of databases which can be leveraged in future projects, many of which revolve around image classification and the needs of deep learning. This said (and as alluded to above), there are at least two additional use-cases in which this project could be utilized:
Tor Traffic Analysis
Mapping the question of how one starts from a surface web-based dark web indexing source, then completes several hops to a specific series of content. This could be accomplished quickly by exporting data from the completed database into a Graph Database Management System (GDBMS) such as Neo4j, but the data required for this type of link-analysis was a primary consideration in the original project outline.
Working with Neo4j, I think that we’ll discover many interesting bottlenecks while searching for specified content, which could be useful to researchers and analysts of many types.
Content Discovery
While impressive, the major index projects often lack accuracy and ability to locate resources or content which violates their loose, sometimes arbitrary code of ethics – which renders them less useful to professional researchers. For several projects I have viewed, this is enforced within the source code through exclusion lists and content classification.
This project features no such controls, as its goal is study the Tor network in as close to it’s entirety as possible.
Upcoming Capabilities
As core components of the project workflow near completion, I plan to bring multi-processing to the some of the more tedious aspects of data enrichment, with which I hope enhance overall performance. Other than this, I hope to integrate the following:
- Enhanced process orchestration from the main script
- Language detection & possibly translation
- Service type Identification
- Forum scraping and indexing
- Chat and Telegram scraping
- Extension into surface web resources, such as X(Twitter), reddit and more.
- Chat, file hosting and email detection.
I will update this post as I roll out new capabilities, but the best place to keep abreast of these is to subscribe to the project’s GitHub repository. https://github.com/TylerG01/onion_scraper
End-State Capabilities
Admittedly, I plan to work to improve the capabilities of the project for some time to come; fine-tuning performance and optimizing workflow, enhancing the data enrichment process and possibly even changing some modules to other programming languages.
With this said, this project is just one within an ecosystem of many others, each serving a unified goal in data collection and enrichment.