
Since 2022, my team and I have deployed this general architecture numerous times under highly analogous circumstance, constraints and production goals. While specific details related to end client(s) have been obfuscated, I felt this architecture was worth sharing due to it’s versatility and performance.
For more general level information on my background, feel free to connect on LinkedIn or view my $ whoami post.
Focus:
In attempt to avoid redundancy, this post will focus on the data pipeline which seeks to accomplish the clients objectives. I will not discuss Microsoft’s Cloud Adoption Framework(CAF), Enterprise Scale Landing Zone(ESLZ), or Well Architected Framework(WAF) principles, as their considerations are inherent in every design project.
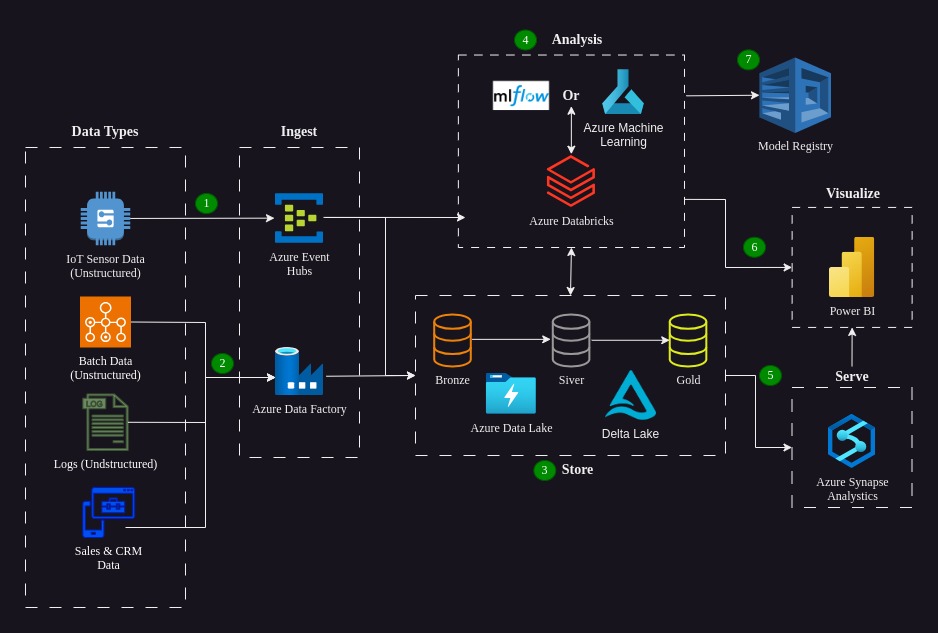
Scenario Overview
A large petrochemical refiner has recently transitioned to a new executive leadership team, which is determined to cut costs and consolidate their data estate while simultaneously realizing tangible benefits from advances in technologies and methodologies. They’ve stated that they would like a data pipeline which produces the following results:
- Migrate stored batch data and historical logs into the cloud.
- Enrich data and establish unified Master Data Management (MDM) data sets
- Build predictive algorithms for maintenance and production configurations.
- Begin to train AI & ML models to assist in low hazard production and scheduling.
- Generate business insights for both commercial account sales, and operations personnel.
Currently, data exists in several forms to include unstructured batch and log data, semi-structured Sales & CRM data on a 3rd party provider’s cloud, and unstructured IoT stream data coming in live from their production locations.
The client plans to utilize in-house cloud admins to maintain the architecture as well as their new subscriptions, and both Data Scientists and Data Engineers to manage the machine learning and AI model development and deployment. As such, they ask that the architecture minimizes personnel and technology overhead where possible.
Workflow
- Stream data from IoT sensors is ingested by Azure Databricks through Azure Event Hubs.
- Unstructured batch data, various log files and app data is ingested from their on-prem stores by Azure Data Factory, then stored in Azure Data Lake Gen2.
- Within the data storage layer, there are several active technologies and methodologies serving the Analysis and Serve layers:
- Azure Data Lake Gen2 is a unified storage (built on Azure Blobs) which can store data of all types, including the batch and stream data show above.
- Delta Lake is the default storage format for all operations on Azure Databricks and forms its optimized storage layer. This architecture also recommends the use of Delta Live Tables(DLT) which simplifies ELT workloads through optimized execution and scaling.
- The Medallion Architecture is recommended by Databricks to process data through a series of tables as data is cleaned and enriched. The quality of data in each layer is represented by bronze (raw), silver (validated) and gold (enriched) stores shown above.
- The Analysis layer utilizes Azure Databricks (Apache Spark included by default) to transform, prepare and enrich data present in the storage layer. mlflow and/or Azure Machine Learning are also used in this layer to quickly identify suitable algorithms and parameters for training machine learning models, provide model registries and assist with deployment of completed models.
- Validated data is served to Azure Synapse Analytics through both Azure Databricks and the storage layer, which is warehoused, analyzed and used to produce real-time insights to support immediate decision making. This is usually more useful to those in operations-based roles.
- Power BI produces analytics, interactive reporting and projections, based on historical records produced by Azure Synapse Analytics, and data enriched by Databricks. These insights are useful for sales and other leaders in the companies sales and performance tracking roles.
- For both mlflow and Azure Machine Learning, their model registries provide a centralized store for model lineage, versioning, tagging, environment perimeters, information on datasets and tools which assist the user with deployment.
Components
Components in present in this architecture are listed in alphabetical order with links leading to their official Microsoft Learn Documentation:
- Azure Databricks: Databricks provides the latest versions of tools (including Apache Spark) that help data science teams connect sources of data to a single, unified platform to process, store, share, analyze and model datasets for a most data tasks.
- Azure Data Lake Storage Gen2: is a centralized repository, whose hierarchical namespace is a key feature that enables Azure Data Lake to provide high-performance data access at object storage scale and price. Built on Azure Blob Storage, it’s ability to store petabyte-sized files, facilitate hundreds of gigabits of throughput, hold trillions of objects and both structured and unstructured data, make Azure Data Lake Gen2 and ideal solution for AI/ML work flows.
- Azure Event Hubs: is a cloud native data streaming service which can ingest millions of streaming data events per second.
- Azure Machine Learning: Azure Machine learning provides an environment to accelerate the creation and simply management of the end-to-end life cycle of machine learning training and development projects.
- Azure Synapse Analytics: Azure’s cloud-based enterprise data analytics that leverages massively parallel processing (MPP) to quickly run complex queries across petabytes of data. Because of this, Azure Synapse Analytics is the ideal solution for real-time visualization of validated production data.
- Azure Synapse Databricks Connector: This connector uses the COPY statement in Azure Synapse to transfer large volumes of data efficiently between an Azure Databricks cluster and an Azure Synapse instance using an Azure Data Lake Storage Gen2 storage account for temporary staging.
- Delta Lake: Delta Lake is the optimized storage layer and default storage format, that provides the foundation for tables in a lakehouse on Databricks.
- Delta Liive Tables(Not Shown): Delta Live Tables simplifies ETL workloads through optimized execution and automated infrastructure deployment
- MLflow: An open-source framework designed to manage the complete machine learning lifecycle. Azure Machine Learning workspaces are mlflow compatible, meaning that you can use it in the same way that you would use an mlflow server.
- Power BI: A business analytics service which analyses historical data to produce visual representations and produce projections for decision makers and leaders of all types.
Development Considerations
Azure offers a wide range of services, platforms and infrastructure capabilities, which are sometimes very similar in nature. As weighing the advantages of similar services can be difficult in many scenarios, I offer the following considerations from this architecture’s development.
Azure Event Hubs vs. Azure IoT Hub
While it is recommended by Microsoft to use Azure IoT Hub to connect IoT devices to your Azure cloud services, the goals of this architecture do not include two-way communications to manage IoT devices, but to ingest telemetry data from sensors and devices in real time, allowing for monitoring, analytics, business intelligence and AI workloads.
Within this context, Azure Event Hubs is capable of handling billions of messages per day, whereas Azure IoT Hub Standard S3 is capable of just 300 million, at nearly 3 times the monthly cost of the former (at the time of this writing).
Medallion Lakehouse Architecture
The medallion architecture is a series of data layers which represent the quality of data stored: raw data (bronze), validated data (silver) and enriched data (gold) are the terms usually used to describe quality of data in each store.
The medallion architecture is recommended by Databricks, and allows for enterprise data products to take a multi-layer approach to consistency, isolation, durability – thus providing an optimized layout for high performance analytics.
Using both Power BI & Azure Synapse
Azure Synapse is designed for limitless scaling to meet data warehouse and analysis for both structured and unstructured data, at enterprise scale. Additionally, Azure Synapse is capable of real-time stream data analysis, providing valuable insights for immediate decisions in a production environment.
On the other hand, Power BI is mainly focused on visualization, reporting and projections based on historical data, but is not designed for real-time analytics. In this architecture, both are utilized to generate insights: One for business personnel and the other for those working in operations.
Closing Thoughts
As an Azure Solutions architect specializing in heavy industry, manufacturing and financial industries, many of the projects I’ve seen over the past 5 – 6 years have sought to perform an ETL process with machine learning model development and business insights as the client’s end goal. While some variation may occur, I have found the above architecture to be repeatable, scalable and flexible enough to advance many business objectives which seek to develop in-house AI or machine learning models with their data, while simultaneously producing actionable business insights and projects.
Thanks for reading and as always, please feel free to reach out via LinkedIn or through the contact form on the page.
Related Post
Case Study: Hybrid Azure Cloud Environment for On-Premises Machine Learning